Today, our Founder Hayden Sutherland, presented the latest developments in Smart Data for the Transport & Mobility sector during a webinar titled “Enhancing transport integration through data-driven analysis”.
The presentation Hayden title “Integrating Transport Customer Data” explained that Transport has made accessing data difficult and that it is becoming more complex.
Data is stored in many different systems, formats and technologies
There are hundreds of different online accounts across the sector (Bus, Rail, Taxi, Micro-Mobility, Air, MaaS, etc.)
The customer must work hard to access all their transport & mobility data
The customer needs to log into every account just to view their own transport tickets and usage data
The Transport Sector has made customer account data sharing difficult. There are now hundreds of different online accounts across the sector (Bus, Rail, Taxi, Micro-Mobility, Air, etc.), meaning each customer must work hard to access all their own transport & mobility data. As an example, just to consolidate their transport expenses, customers need to log in to multiple accounts to view and export their transport tickets and usage information. Plus, GDPR individual rights are ignored, such as The Right to Data Portability, which allows users the ability to “move, copy or transfer personal data easily from one IT environment to another in a safe and secure way, without affecting its usability”: https://ico.org.uk/for-organisations/uk-gdpr-guidance-and-resources/individual-rights/individual-rights/right-to-data-portability/
This difficulty is perpetuated by:
The need for transport operators (and their technology suppliers) to keep data sources under their control, with each still wanting to ‘own’ their relationship with their customers.
The lack of available customer account data sharing examples (pilots or full implementations).
To therefore drive the adoptions of Smart Data sharing across the wider transport sector the following is recommended:
Transport sector stakeholders must provide strategic guidance and sponsorship of customer account data pilots and projects – for example the recently announced Smart Data Challenge https://smartdata.challenges.org/
Transport data subject matter experts need to fully understand the role of Smart Data and its potential benefits across the sector – for example that it is still possible for transport operators to ‘own’ their relationship with their customers whilst still allowing them to share their account data with Authorised Third Parties [ATPs)]
Technologists need to familiarise themselves with the existing Open Standards for transport & mobility-specific data sharing and also contribute to their ongoing development and sector suitability: https://opentransport.co.uk/open-standard/
Customer account interoperability for any new Public Sector transport service or platform, for any mode, must be mandated (e.g. to ensure full compliance with GDPR) and then designed into all solutions from the onset, thus kick-starting the market and acting as implementation exemplars for the private sector to follow.
This week sees the announcement of the Smart Data Challenge Prize. This is a £600,000 pot funded by the Department of Business and Trade, designed to identify and develop Smart Data use cases across the economy. “The Prize will give up to ten selected innovators the opportunity to prototype Smart Data solutions with high potential impact in a specially created Data Sandbox.”
The Open Transport welcomes the launch Smart Data Challenge Prize and is also strongly considering submitting an application. We are therefore very keen to work with and potentially jointly applying for this challenge with other organisations across the transport & mobility sector.
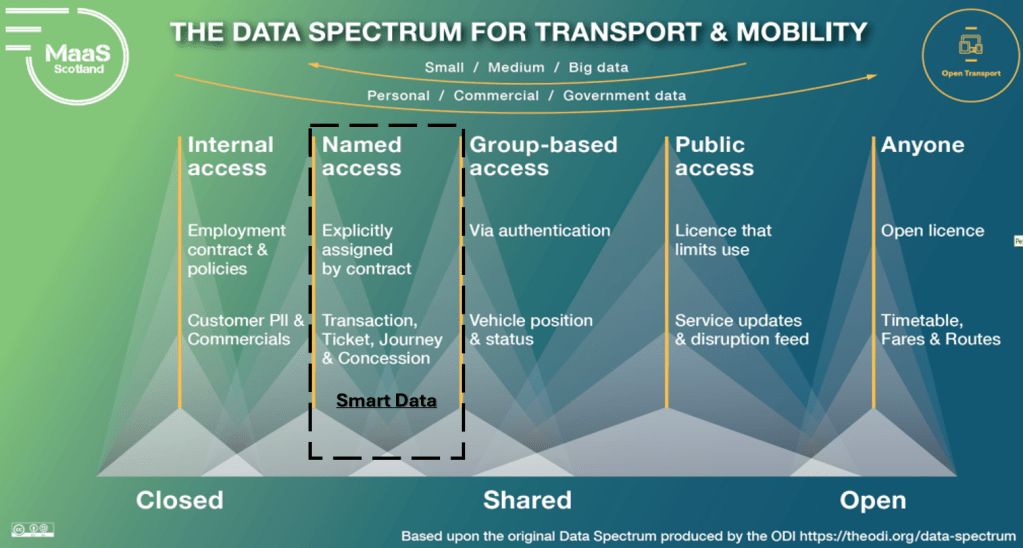
Several years back we worked with MaaS Scotland (the umbrella organisation for Mobility-as-a-Service [MaaS] activities in Scotland) on the creation of The Data Spectrum for Transport & Mobility.
This diagram was a small (but significant) step forward in the data maturity of the sector. In that it adopted the original work of The Open Data Institute and aligned transport & mobility to data terminology already used by other sectors such as banking, energy, and smart cities. https://opentransport.co.uk/2021/06/23/launching-the-data-spectrum-for-transport-mobility/
More recently, and with the more common use of the term Smart Data to the secure sharing of customer data with Authorised Third Parties [ATPs], we have been asked where this sort of data (e.g. transactions, journey history and discounts & concessions) sits within the Data Spectrum.
Luckily, its position is easy to spot… as it is a particular sort of data that is shared securely with authorised (named) parties with the customer’s permission (a data sharing contract). And consequently can be thought of as ‘Named Access’ data that sits in the area outlined below.
If you would like to join or know more about the work of the Open Transport Initiative please contact us: contact@opentransport.co.uk
In October this year several organisations were invited to a Smart Transport Data Roundtable in Leeds organised by Intelligent Transport Systems UK (ITS UK), the industry body for transport technology, and the Open Data Institute (ODI).
At this Roundtable the role of smart data in a transport context was discussed, learnings from other industries where smart data has progressed were shared and participants discussed what a smart data approach could mean for transport providers and suppliers, the Mobility-as-a-Service (MaaS) sector and the wider transport network.
At the end of the meeting it was agreed by the attendees that a regular meeting should be held, to continue the momentum from the day and move the topic forward. This then led to the first “Smart Data 4 Transport” group meeting that happened this week.
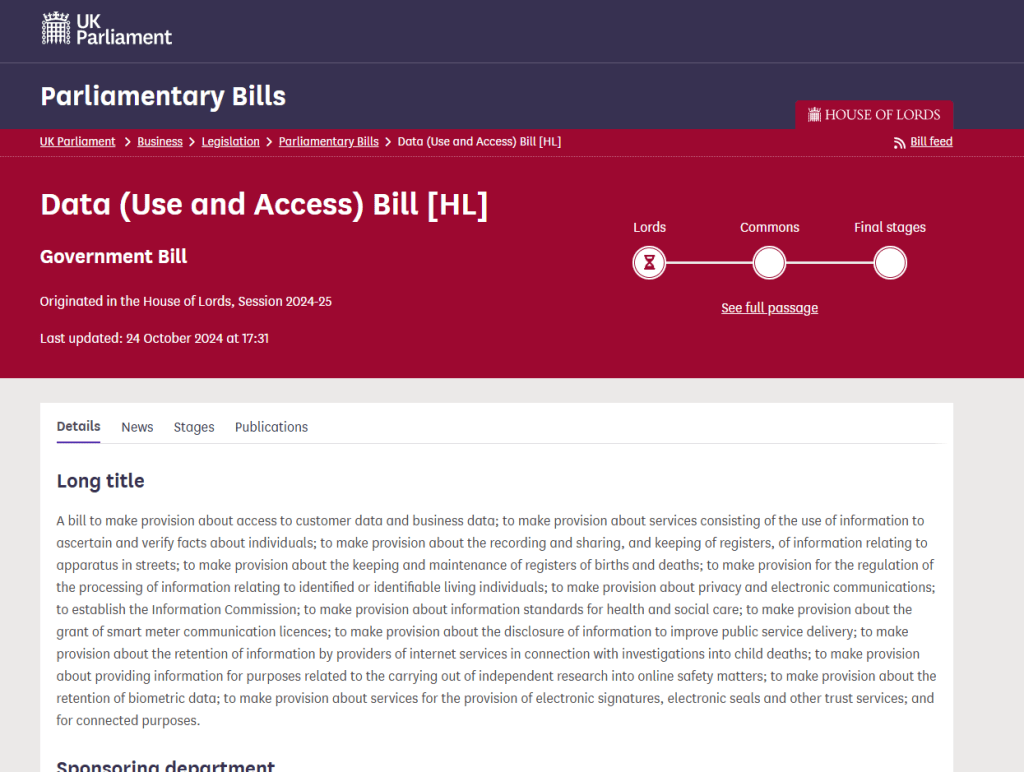
A newly renamed Data Use and Access Bill was been introduced to Parliament on Wednesday 23rd October 2024. This creates the conditions for the future success of Open Banking and the growth of other Smart Data schemes.
Disappointingly, there was no specific mention of the Transport & Mobility sector in the announcement.
But the wording of the Bill is encouraging:
“The Bill, delivered by the Department for Science, Innovation, and Technology, has three core objectives: growing the economy, improving UK public services, and making people’s lives easier. The measures will be underpinned by a revamped Information Commissioner’s Office, the UK’s independent authority responsible for regulating data protection and privacy laws, with a new structure and powers of enforcement – ensuring people’s personal data will be protected to high standards.”
The following is a post originally published on our company LinkedIn page, but now copied here for reference:
Smart Data? For those that are not familiar with this term, Smart Data is the secure sharing of customer data with authorised third parties (ATPs). The most popular example of Smart Data is Open Banking, introduced via legislation in January 2018. Back then it forced the UK’s nine biggest banks (HSBC, Barclays, RBS, Santander, Bank of Ireland, Allied Irish Bank, Danske, Lloyds and Nationwide) to allow data they held online to be shared with authorised organisations in a secure, standardised form. Open Banking has then fuelled the FinTech sector, one of the UK’s economic success stories of the last decade. Note: Other terms such as “Open X”, “Open Economy” and “Open Everything” have also been used, to various degrees, in the past. But the UK Government has chosen and used the term “Smart Data” for the last few years… so those who work in and around the topic of data sharing have also adopted and embraced it.
This paper clearly stated that : “the government wants to see similar and interoperable schemes in sectors beyond retail banking to realise a world-leading Smart Data economy”
What is a Smart Data economy? With the success of Open Banking, the aim of UK Government is now to ‘open up’ customer data sharing across different sectors of UK industry such as: energy, finance, home buying, retail, telecommunications and transport. This will, as a result:
empower consumers and small business customers – putting them in control of their own data
turbo charge competition, innovation and growth – removing data ‘lock-in’ created by anti-competitive practices
unlock the potential for smart data to drive the wider data economy
Note: The origins of the Smart Data economy are actually based upon the UK Government Data Strategy (2017 updated 2023) that set out how to unlock the power of data in the UK economy: “To support industry in unlocking value from data, we will work with organisations such as the Open Data Institute to create an environment to open up customers’ data across more sectors through the use of APIs (Application Programming Interfaces). This will help the development of innovative new applications, such as dashboards that bring together household bills, or tools that could automatically switch consumers to the cheapest energy deal based on their preferences and actual usage. The UK is the first country to start work on developing an Open Banking API that uses data to provide helpful information to consumers when using banking services.” https://www.gov.uk/government/publications/uk-digital-strategy/7-data-unlocking-the-power-of-data-in-the-uk-economy-and-improving-public-confidence-in-its-use
Will a Smart Data Economy bring economic benefit? Yes, the UK Gov Digital Strategy has stated that building a Smart Data economy could unlock £149 billion of organisational efficiency and £66 billion of new business and innovation opportunities in the UK economy. Meaning the Smart Data economy is potentially worth a total of £215 billion over five years… if implemented properly and completely.
How can we build a Smart Data Economy? Creating the world’s first Smart Data economy will not be plain sailing. There are a number of steps necessary to build and maintain it, including the introduction of legislation to create statutory powers to introduce separate Smart Data schemes. But just this week, in the Kings Speech (17 July 2024) the new UK Government confirmed the introduction of a Digital Information and Smart Data Bill. Which includes setting up Smart Data schemes in different sectors. https://assets.publishing.service.gov.uk/media/6697ac9cab418ab05559271d/King_s_Speech_2024_background_briefing_GOV.uk.pdf
Don’t forget the Transport & Mobility sector The Smart Data Roadmap, has 4 different maturity phases for the complete introduction of sector-specific schemes: 1. identification 2. consultation 3. design 4. implementation
The success of Open Banking has also understandably led to a focus on related areas. But the full benefits of a Smart Data Economy cannot be realised without including other important sectors, these (along with their Roadmap maturity) are:
Finance (Identification)
Energy & Road Fuels (Identification and Consultation)
The next steps in the Smart Data roadmap for Transport now sit with UK Department for Transport [DfT] to progress.
These steps include:
Taking forward discovery work to develop transport use cases for Smart Data.
Using the outcomes of the discovery to shape the evidence for a Call for Evidence in Autumn 2024, along with potential questions.
Publishing further detail on the opportunities for Smart Data in the transport sector in 2025.
Who is working to implement Smart Data in our sector? The Open Transport Initiative has been working towards the introduction and establishment of Smart Data sharing in Transport & Mobility for several years. The organisation was specifically set-up in 2019 to drive forward the adoption of “Open Banking” data sharing practices across the sector. Their aim has been to engage with providers, authorities and government to support the uniform & standardised implementation of such a Smart Data scheme. https://opentransport.co.uk/
This work even includes the creation & publication of Open Standard (free to use) APIs, which should help vendors and developers to deliver the technical changes needed. https://opentransport.co.uk/open-standard/
If you would like to join or know more about the work of the Open Transport initiative content them via: contact@opentransport.co.uk
A Smart Data Economy is the roll-out of Open Banking-like data sharing across sectors, including: energy, finance, home buying, retail, telecommunications and transport.
The UK Gov Digital Strategy has stated that building a Smart Data economy could unlock £149 billion of organisational efficiency and £66 billion of new business and innovation opportunities in the UK economy.
empower consumers and small business customers – putting them in control of their own data
turbo charge competition, innovation and growth – removing data ‘lock-in’ created by anti-competitive practices
unlock the potential for smart data to drive the wider data economy
The origins of the Smart Data economy are actually based upon the UK Government Data Strategy (2017 updated 2023) that set out how to unlock the power of data in the UK economy:
“To support industry in unlocking value from data, we will work with organisations such as the Open Data Institute to create an environment to open up customers’ data across more sectors through the use of APIs (Application Programming Interfaces). This will help the development of innovative new applications, such as dashboards that bring together household bills, or tools that could automatically switch consumers to the cheapest energy deal based on their preferences and actual usage. The UK is the first country to start work on developing an Open Banking API that uses data to provide helpful information to consumers when using banking services.”
The King’s Speech today covered the introduction of the Digital Information and Smart Data Bill.
This includes: “setting up Smart Data schemes, which are the secure sharing of a customer’s data upon their request, with authorised third-party providers”.